One interview, 1000+ job opportunities
Take a 10-min AI interview to qualify for numerous real jobs auto-matched to your profile 🔑
Google engg beating the drum on google stuff which can’t even defeat sonnet on the only benchmark that matters swebench. Even which is kinda a lul coz it has only python tasks. And multi swe bench , poly swe bench, and other diverse versions are also there.
Why: see AIME with code exec sonnet gets same performance as gemini 3 pro coz code execution is the only thing that matters at the end. You can manipulate applications through it, manipulate os, provide tools, manipulate browser and webpages. Basically the mangnum opus of automation is code. So only code benchmarks matter rest is already history.
Also would be good to see how much of the other improvements in performance is just benchmark grokking and test data contamination.
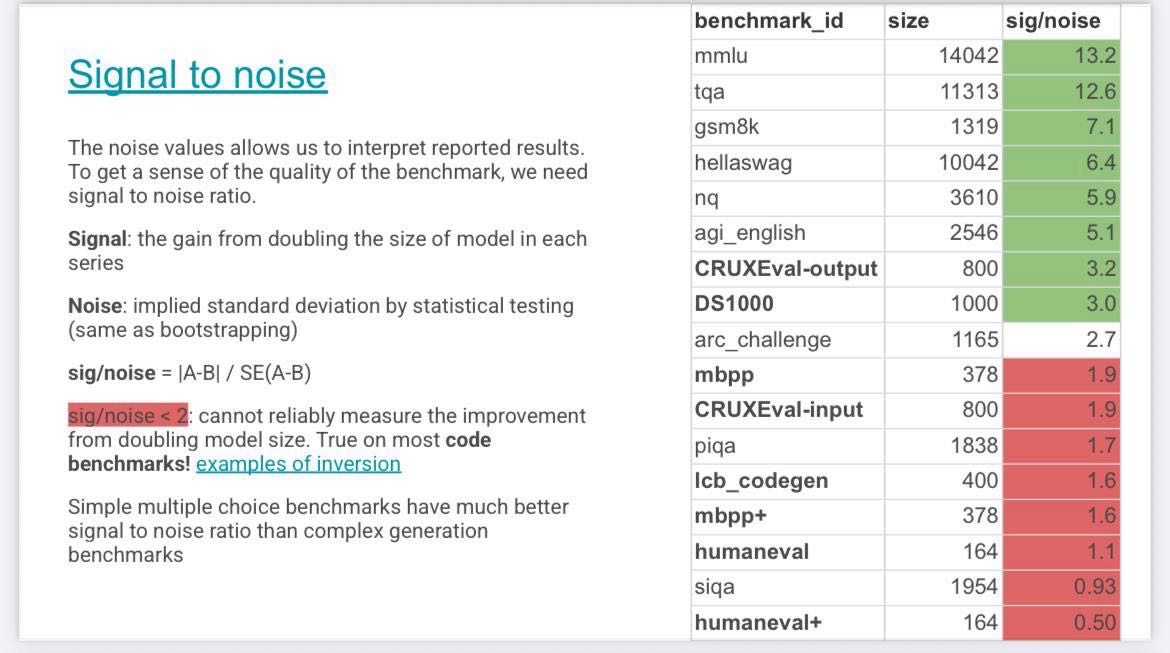
At the same time recent research suggest most of the code benchmarks have high signal to noise ratio and are the most unreliable😂. Welcome to ai evals.
https://github.com/crux-eval/eval-arena?tab=readme-ov-file#signal-to-noise-ratio