
JumpyTaco
19moBreakthrough in Test-Time Compute
I came across two interesting papers recently on scaling laws in AI and wanted to share a summary. Here are the key takeaways:
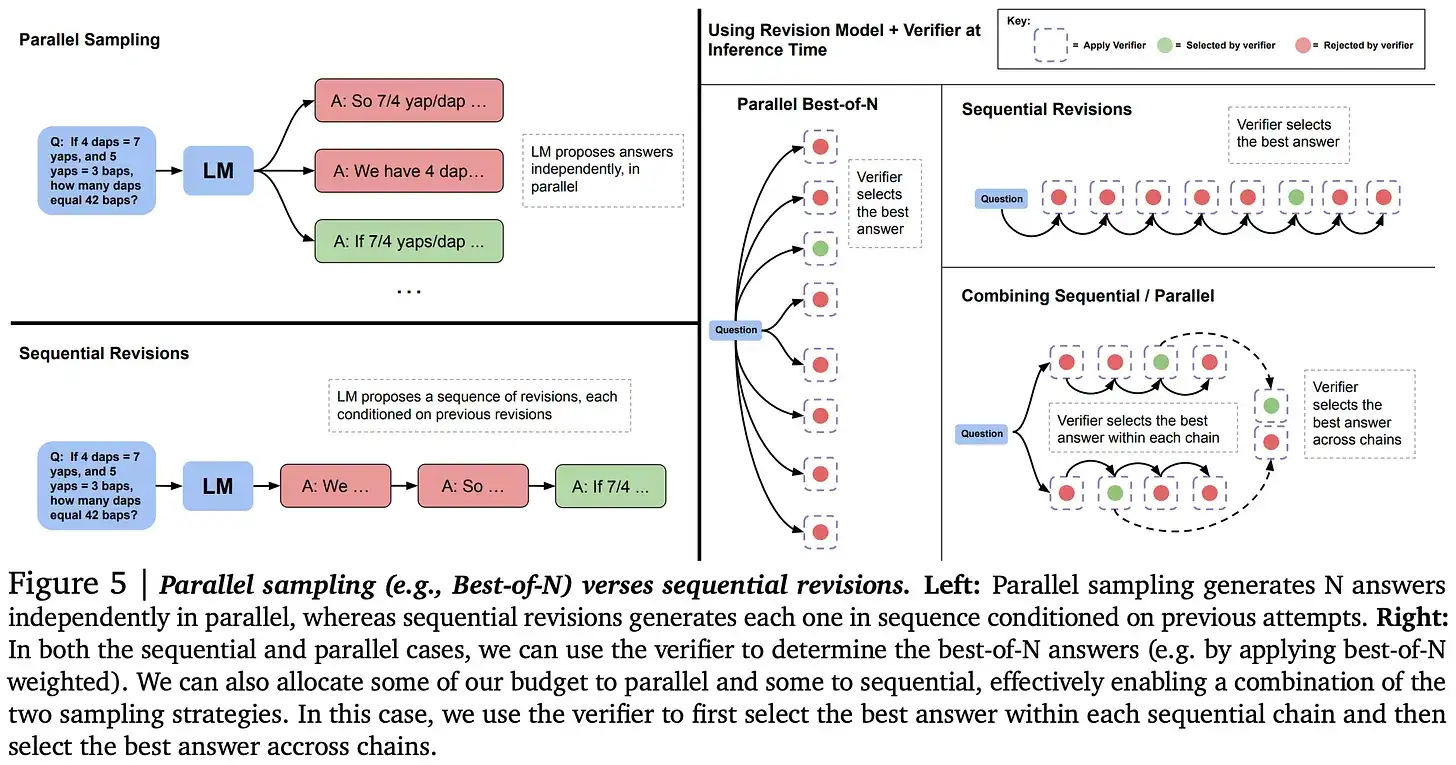
Scaling LLM Test-Time Compute Two papers looked at how to scale up test-time compute for LLMs:
- Simple strategies like weighted voting keep improving as you scale up test-time compute
- There's a regime where recognizing good solutions becomes the bottleneck, not generating them
- The ratio of test-time to training-time compute is increasing
- Batch size 1 inference may become less important; parallel generations could become standard
- Tree search with Process Reward Models is emerging as a legitimate strategy
- We may see more compound systems with separate proposer and verifier modules
Finetuning Effects A study on finetuning 1-16B param LLMs found:
- Model size matters more than finetuning dataset size
- Pretraining dataset size matters more than finetuning dataset size
- Finetuning dataset size matters way more than params added by PEFT methods
- Power law curves fit the results well, but coefficients vary by method/task
19mo ago

You're early. There are no comments yet.
Be the first to comment.
Discover more
Curated from across

